Foundation Models for 3D Humans
ECCV 2024 Workshop
September 30, 2024, PM Mico Milano, Italy
Overview
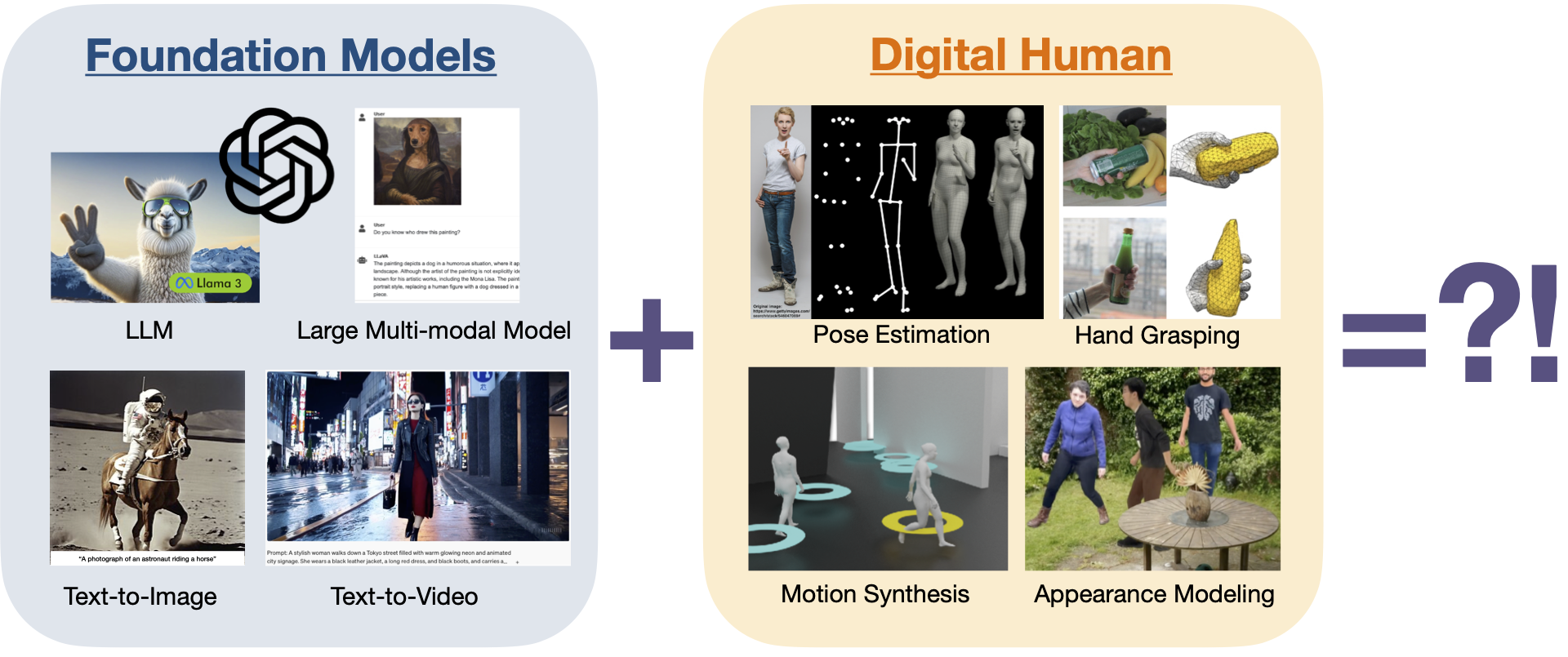
Foundation models (e.g., large language models (LLMs), large vision models, text-to-image generative models) are impacting nearly every area of computer vision and represent a paradigm shift from end-to-end learning of task-specific models to pretraining-finetuninng generalist models. Such a paradigm shift urgently calls for rethinking the new challenges and opportunities in the study of digital humans. This workshop is particularly focused on exploring two key questions: (1) how foundation models can help the study of digital humans; (2) how we can build foundation models for digital humans. The study of digital humans encompasses a wide breadth of research areas, from high-fidelity digital avatar modeling and lifelike human motion generation to human animation and behavior analysis. This workshop offers an in-depth exploration of the vibrant intersection between 3D digital human modeling and foundation models. We plan to bring experts in general foundation models and experts in 3D digital humans together to exchange ideas and discuss open challenges.
Invited Speakers





Workshop Schedule
Room: Tower Lounge
| Time | Topic |
|---|---|
| 2:00PM - 2:10PM | Welcome and Opening Remark |
| 2:10PM - 2:40PM | Siyu Tang: Learning foundation models for 3D humans: a data request video |
| 2:40PM - 3:10PM | Xavier Puig: Human Models for Embodied AI video |
| 3:10PM - 3:40PM | Jingyi Yu: Towards Anatomically Correct Digital Human: From Imaging to Foundation Models video |
| 3:40PM - 4:20PM | Coffee Break & Poster & Demo |
| 4:20PM - 4:50PM | Michael Black: Towards the 3D Human Foundation Agent pdf |
| 4:50PM - 5:20PM | Angjoo Kanazawa: Hard problems that need to be solved for 3D human foundation models pdf |
| 5:20PM - 6:00PM | Panel Discussion and Closing Remark |
Awards
Best Paper Award
BodyShapeGPT: SMPL Body Shape Manipulation with LLMsBaldomero R. Árbol, Dan Casas, Universidad Rey Juan Carlos
Best Poster Award
N Heads Are Better Than One: Exploring Theoretical Performance Bounds of 3D Face Reconstruction MethodsWill Rowan, Patrik Huber, Nick Pears, Andrew Keeling, University of York, University of Leeds
Accepted Papers
archival
BodyShapeGPT: SMPL Body Shape Manipulation with LLMsBaldomero R. Árbol, Dan Casas, Universidad Rey Juan Carlos
Photorealistic Text-to-3D Avatar Generation with Constrained Geometry and AppearanceYuanyou Xu, Zongxin Yang, Yi Yang, Zhejiang University, Harvard University
MCRE: Multimodal Conditional Representation and Editing for Text-Motion GenerationTengjiao Sun, Xiang Li, TIANYU SHI, Jiahui Peng, Sheng Zheng, Hansung Kim, University of Southampton, Southern University of Science and Technology, University of Toronto, McGill University, effyic co. ltd.
Towards motion from video diffusion modelsPaul Janson, Tiberiu Popa, Eugene Belilovsky, Concordia University
N Heads Are Better Than One: Exploring Theoretical Performance Bounds of 3D Face Reconstruction MethodsWill Rowan, Patrik Huber, Nick Pears, Andrew Keeling, University of York, University of Leeds
GECO: GPT-Driven Estimation of 3D Human-Scene Contact in the WildChaehong Lee, Simranjit Singh, Michael Fore, Georgios Pavlakos, Dimitrios Stamoulis, Microsoft, University of Texas at Austin
MI-NeRF: Learning a Single NeRF for Multiple IdentitiesAggelina Chatziagapi, Grigorios Chrysos, Dimitris Samaras, Stony Brook University, University of Wisconsin-Madison
PlaMo: Plan and Move in Rich 3D PhysicalAssaf Hallak, Gal Dalal, Chen Tessler, Kelly Guo, Shie Mannor, Gal Chechik, NVIDIA Research
non-archival
MaskedMimic: Unified Physics-Based Character Control Through Masked Motion InpaintingChen Tessler, Yunrong Guo, Ofir Nabati, Gal Chechik, Xue Bin Peng
Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single ShotFabien Baradel, Matthieu Armando, Salma Galaaoui, Romain Brégier, Philippe Weinzaepfel, Grégory Rogez, Thomas Lucas
F-HOI: Toward Fine-grained Semantic-Aligned 3D Human-Object InteractionsJie Yang, Xuesong Niu, Nan Jiang, Ruimao Zhang, Siyuan Huang
PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose RepresentationGinger Delmas, Philippe Weinzaepfel, Francesc Moreno-Noguer, Grégory Rogez
MotionScript: Natural Language Descriptions for Expressive 3D Human MotionsPayam Jome Yazdian, Eric Liu, Rachel Lagasse, Hamid Mohammadi, Li cheng, Angelica Lim
Reviewers
Peizhuo Li, ETH Zurich
Korrawe Karunratanakul, ETH Zurich
Siyao Li, Nanyang Technological University
Jing Lin, Tsinghua University
Yu Sun, Meshcapade
Siyuan Bian, Shanghai Jiaotong University
Tingting Liao, MBZUAI
Zeyu Cai, HKUST(GZ)







